
前提
pythonの"tabula"を使って、PDFの表をCSVに出力するようなものを作っています。
実現したいこと
読み込むPDFの表に合わせてカラム数も変更できるようなプログラムを考えていること。
特殊な表の場合,同じもしくは近い形でCSVに抽出できるかを模索しているところです。
上記記載のプログラムを作ることは可能でしょうか?
発生している問題・エラーメッセージ
エラーメッセージ "ValueError: Length mismatch: Expected axis has 6 elements, new values have 5 elements"
該当のソースコード
Python
import os import pandas as pd from IPython.core.display import display import tabula ###PDFファイルパスpath_name = 'data/log.pdf' ###PDFの読み込みdfs = tabula.read_pdf(path_name, guess=True, pages='all', stream=True, area='emtire')print(dfs[0])# データフレーム保存用リストdf_all = []a = '取引日付'b = '取引内容'c = '出金'd = '入金'e = '残高' ## ###読み込んだPDFの整形for df in dfs: df.columns = [a, b, c, d, e] #リストに追加 df_all.append(df) # print(df_all) #全てのデータフレームを結合 df = pd.concat(df_all) display(df_all) # ##CSVに出力os.makedirs("SaveFolder", exist_ok=True)for i, df in enumerate(df_all): df.to_csv("SaveFolder\\result{}.csv".format(i), index=False)# df_all.to_csv("SaveFolder\\result.csv", index=None)print('出力しました')``` ### 試したこと ・pyocr経由で一旦テキストを取得して表にコピペ(OCRの読込が不安定すぎて断念) ・tabulaではなくCamelotを使おうとしましたが、「"AttributeError: module 'camelot' has no attribute 'read_pdf'」が解決できず試せていない。 ・「tabula.read_pdfの引数にguessとareaを入れて指定したが変化なし 情報(FW/ツールのバージョンなど) windows10 python3.9anaconda3.9pycharm2022.2.3 pandas == 1.5.1tabula == 1.0.5PySimpleGUI == 4.60.4pyinstaller == 5.6.2 読み込むファイルのサンプル 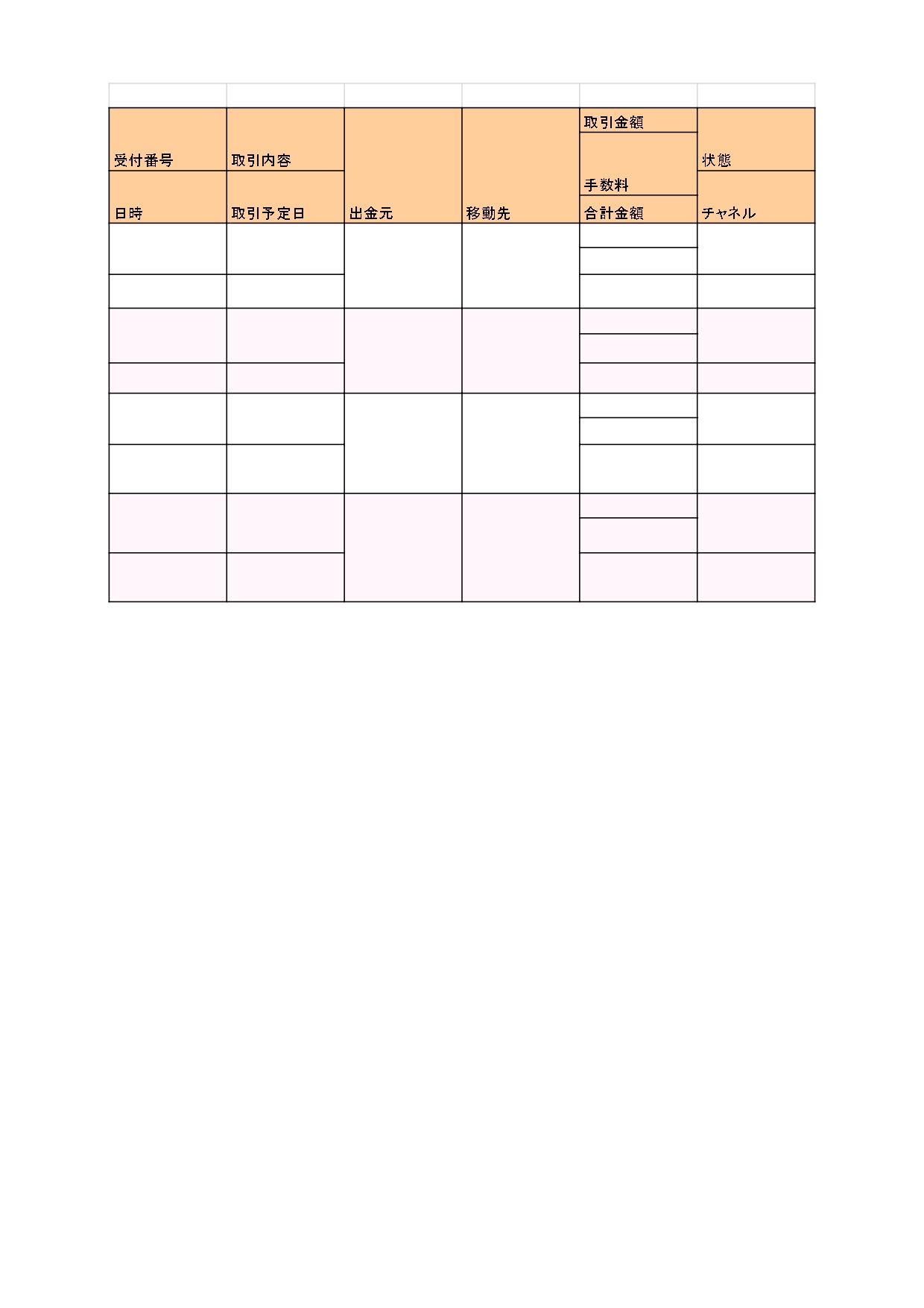



0 コメント