
実現したいこと
webサイトの表を取得したいという話なのですが、
少し複雑なのが、複数サイトの表を1つのcsvファイルにまとめたいため、
証券番号をgoogle検索→1番目のサイトのURLを取得→複数サイトのURLをリスト化→forで各サイトの表を取得しcsvへ
という流れです。
前提
https://www.ipokiso.com/company/2023/ridge-i.html
https://www.ipokiso.com/company/2023/globee.html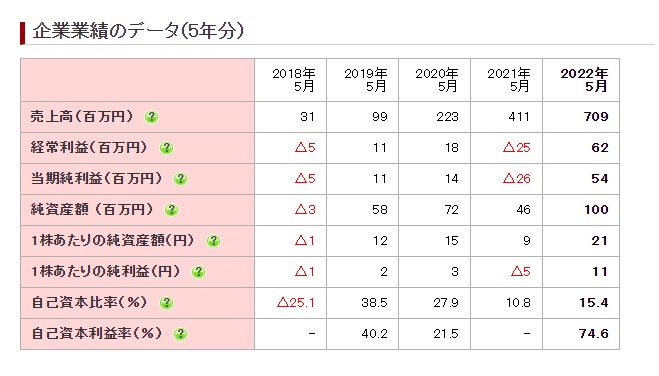
・上記が該当サイト、該当の表です。(表の指定までは上手く書けておりません。まずは何でもいいので表データを取得できればと思って書きました。)
・pandasの、pd.read_html を用いて表を取得しようとしました。
できれば業績データのみ取り出したいと思っています。
・csv出力に関しては、以前の質問で書いて頂いたコードを参考にしています。
全然異なるやり方でも大丈夫でございます。
発生している問題・エラーメッセージ
DevTools listening on ws://127.0.0.1:61331/devtools/browser/7c43ece5-c416-4fac-823d-84917d6f72b4 ['ipokiso.com\nhttps://www.ipokiso.com › company › halmek-holdings', 'ipokiso.com\nhttps://www.ipokiso.com › company › ibis'] C:\Users\ukata\AppData\Local\Programs\Python\Python311\Lib\site-packages\pandas\io\html.py:674: MarkupResemblesLocatorWarning: The input looks more like a filename than markup. You may want to open this file and pass the filehandle into Beautiful Soup. soup = BeautifulSoup(udoc, features="html5lib", from_encoding=from_encoding) not found stock table
該当のソースコード
Python
1# インポート2from selenium import webdriver 3from selenium.webdriver.common.by import By 4from selenium.webdriver.common.keys import Keys 5import time 6from selenium.webdriver.chrome import service as fs 7CHROMEDRIVER = "C:\chromedriver_win32\chromedriver.exe"8chrome_service = fs.Service(executable_path=CHROMEDRIVER) 9browser = webdriver.Chrome(service=chrome_service)10 11# 証券番号12numbers = ['7119', '9343']13 14list_urls = []15for xx in numbers:16 17# IPOkiso にアクセスして証券番号を検索18 browser.get('https://www.ipokiso.com/index.html')19 time.sleep(1)20 search_box = browser.find_element(By.NAME, "q")21 search_box.send_keys(xx)22 search_box.send_keys(Keys.RETURN)23 time.sleep(1)24 25# URLを取得する26 site_url = browser.find_element(By.CLASS_NAME,"TbwUpd").text 27 list_urls.append(site_url)28 29print(list_urls)30 31# CSV出力32import pandas as pd 33import sys 34import ssl 35ssl._create_default_https_context = ssl._create_unverified_context 36 37dfs = []38for url in list_urls:39 try:40 df = pd.read_html(url)41 dfs.append(df[0])42 except ValueError:43 print('not found stock table', file=sys.stderr)44 break45else:46 df = pd.concat(dfs, ignore_index=True)47 df.to_csv('out.csv', index=False, encoding='shift-jis')
試したこと
pandasを使う他、find_elementで表を取得しようとも頑張りましたがうまくいかず
補足情報(FW/ツールのバージョンなど)
windows10,python3.11

0 コメント